分布式数据库存储设计的革新 构建高效、可靠的数据处理与存储支持服务体系
随着数据量的爆炸式增长与业务复杂性的不断提升,传统的集中式数据库架构在扩展性、可用性和性能方面面临严峻挑战。分布式数据库以其水平扩展、高可用和地理分布等核心优势,成为支撑现代海量数据处理与存储的关键基础设施。一个强大的分布式数据库不仅依赖于其基础理论,更取决于其底层存储设计的先进性与健壮性。本文将探讨分布式数据库存储设计的核心改进方向,并阐述其如何为上层的数据处理与存储支持服务提供坚实、高效的基石。
一、 分布式数据库存储设计的核心改进
分布式数据库的存储设计已从简单的数据分片,演进为集智能数据分布、混合存储引擎、高效一致性协议与硬件协同优化于一体的复杂系统工程。
1. 智能数据分布与负载均衡
早期的分片策略(如范围分片、哈希分片)虽然简单,但容易导致数据热点和负载不均。现代分布式数据库引入了更智能的动态分片与负载感知策略。系统能够实时监控各节点的负载(CPU、内存、I/O、网络),并结合数据访问模式,动态迁移数据分片,实现全局负载均衡。例如,将频繁访问的“热数据”自动复制到多个节点,或将大表与相关小表进行协同分片(Co-partitioning),减少分布式连接的开销。
2. 多模与混合存储引擎
单一存储引擎难以满足OLTP(联机事务处理)、OLAP(联机分析处理)、时序、图等多样化工作负载的需求。因此,存储层设计趋向于采用“多模”或“分层混合”架构。在同一数据库内核下,集成行式存储(针对高并发点查与更新)、列式存储(针对大规模分析扫描)、内存存储(针对极致延迟要求)以及对象存储(针对冷数据归档)。通过统一的SQL接口和事务层,实现数据的无缝访问与跨引擎事务,为复杂业务场景提供一站式的数据处理支持。
3. 一致性、可用性与分区容忍性的新平衡
CAP定理是分布式存储设计的理论基础。在实践中,系统不再简单地在CP(一致性与分区容忍性)和AP(可用性与分区容忍性)之间二选一。通过改进的一致性协议(如Raft、Multi-Paxos的变种)和灵活的隔离级别配置,系统可以在不同业务场景下提供最合适的保证。例如,对核心交易采用强一致性,对用户画像分析则采用最终一致性,从而在保证数据正确性的同时最大化系统整体吞吐与可用性。
4. 持久化与存储硬件的协同优化
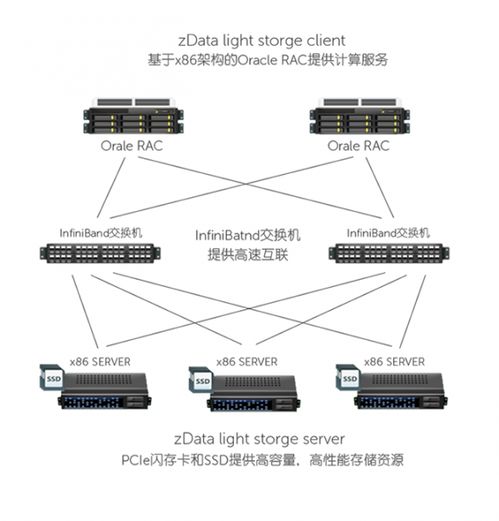
硬件的发展,特别是NVMe SSD、持久内存(PMem)、RDMA高速网络和可计算存储的普及,深刻改变了存储层的设计。新的存储引擎会针对这些硬件的特性进行深度优化:利用PMem的低延迟特性作为WAL(预写日志)或缓存层;利用RDMA实现节点间高效的数据同步与备份;利用NVMe的高IOPS处理高并发请求。这种硬件感知的设计极大释放了硬件潜能,降低了尾部延迟。
5. 全局一致性与分布式事务的增强
跨分片、跨地域的分布式事务是业务开发的一大痛点。存储设计的改进体现在两个方面:一是提供更高效、侵入性更小的分布式事务协议(如Google Spanner的TrueTime启发下的混合逻辑时钟);二是与事务处理层更紧密地集成,通过优化锁管理、提交协议(如两阶段提交的优化版本)和冲突检测机制,在保证ACID特性的将事务开销降至最低。
二、 赋能数据处理与存储支持服务
上述存储设计的根本目标,是为上层的数据处理与应用提供强大、透明、易用的支持服务。
1. 弹性伸缩与资源管理服务
基于智能数据分布的存储层,数据库服务能够实现真正的弹性伸缩。业务无需停机或手动干预,即可根据流量高峰低谷,自动增加或减少计算与存储节点。存储层负责在后台平滑地完成数据重分布,对上层的查询处理引擎完全透明,确保了服务的连续性。这为云原生环境下的按需付费和成本优化提供了可能。
2. 高可用与容灾备份服务
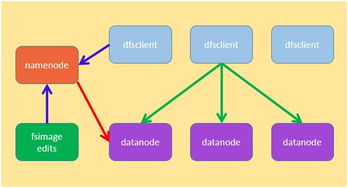
改进的复制与一致性机制,使得构建跨机房、跨地域的高可用架构变得简单可靠。存储层内置的多副本机制(通常为三副本或以上)确保单点故障不影响数据可用性。结合异步或半同步的异地复制,可以提供从同城双活到两地三中心乃至全球多活的容灾能力。这些复杂的复制、故障检测与切换逻辑,均由存储层自动化完成,对应用表现为一个始终可用的数据服务端点。
3. 统一的数据生命周期管理服务
混合存储引擎架构使得数据库能够内建完善的数据生命周期管理策略。根据数据的访问频率、重要性(热、温、冷),存储层可以自动将数据在不同性能/成本的存储介质(如内存、SSD、HDD、对象存储)间迁移。例如,将超过30天未访问的订单明细从行存归档到列存或对象存储,在节省成本的依然支持历史数据的分析查询。这极大地简化了数据治理的复杂度。
4. 高性能与多样化计算支持服务
强大的存储层是高性能计算的基石。对于实时分析场景(HTAP),存储层通过列式存储、向量化执行和内存计算提供亚秒级的复杂查询响应。对于机器学习场景,存储层可以通过高效的数据格式(如Apache Arrow)与计算框架(如Spark、Flink)深度集成,实现数据零拷贝访问,加速特征工程和模型训练。存储设计的改进,使得单一数据库系统能够同时胜任事务处理和数据分析,减少数据搬运,实现数据价值的即时挖掘。
###
分布式数据库存储设计的持续改进,正从底层重塑数据处理与存储支持服务的能力边界。它不再仅仅是一个被动的数据“仓库”,而是演变为一个能够智能调度数据、理解负载特征、协同硬件性能、并保障全局一致性的“主动式”数据服务平台。随着存算进一步分离、AI for DB(利用AI优化存储与管理)以及新硬件技术的成熟,存储设计将继续深化其作为数据处理核心引擎的角色,为企业数字化转型提供更敏捷、更经济、更智能的数据基石。
最新产品